Questions to address/reasons for research
- Is there a better way for us to scale the pipeline apart from each chain having their own pipeline?
- Current pipeline relies on a single instance of kafka – what happens in the event that instance goes down?
- Kafka has to have a way to support redundancy, how is it being handled and how do we set it up?
- Improve understanding of kafka in general.
Summary
- Kafka zookeeper handles the management of kafka brokers (servers).
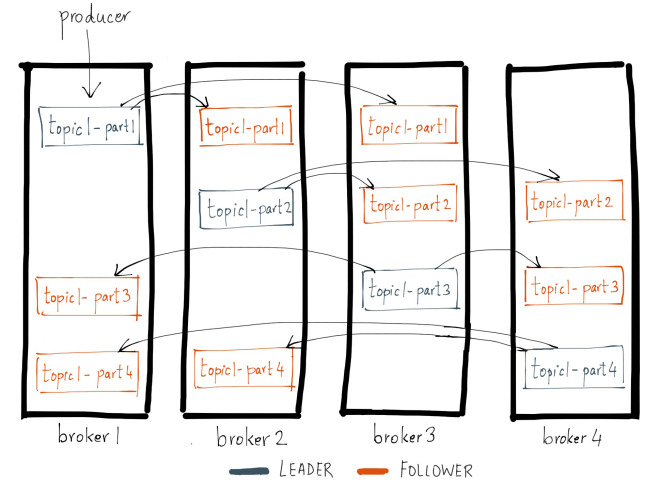
- Replication factor is configurable (recommended: >1)
- Think of RAID 5 but replace parity for topics. (See Kafka replication visualised)
Kafka "TLDR"
Information is obtained from [this playlist from Confluent](https://www.youtube.com/watch?v=qu96DFXtbG4&list=PLa7VYi0yPIH0KbnJQcMv5N9iW8HkZHztH&index=2). 1. Internally stores events (messages) as k-v pairs. - keys _can_ be serialised objects, but are often primitives - because of this keys are not necessarily UIDs for the event (message ID) 2. Topics are not indexed, access by offset - offset = currentKey + currentMsgInBytes (TBC; similar to accessing next value in array by pointers(?)) 3. **Topics != queues -> consumption does not remove it from the topic unless configured otherwise (age/size)** 4. Partitions -> similar to RAID 0, data is striped across partitions - If no key specified to message, round-robin distribution, - Else it goes through a hash function to determine the partition number (similar to hashmap) 5. Producers decides on which petition the message gets sent to (standard/custom config)
Other considerations
- Single topic with different keys, vs Different topic with null keys.
- Currently implemented by different topics, no reason to change unless using keys makes more sense or has better performance.
Resources
- http://notes.stephenholiday.com/Kafka.pdf
- Kafka replication documentation
- Hands-Free Kafka Replication: A Lesson in Operational Simplicity
- Kafka topic replication configuration
Kafka replication visualised
 (source: confluent)
(source: confluent)